
Why did we build Seeq Data Lab?
Industrial Analytics Can Benefit Greatly from the Meteoric Rise of Technologies like Jupyter Notebooks, Pandas Dataframes, and Python.
In March of 2019, a colleague of mine asked if I could help him figure out how to better use Seeq’s REST API from Python. This was not an uncommon request: Since everything that is possible to do in Seeq applications (Workbench and Seeq Organizer) is also possible to do programmatically with our REST API, many Seeq users are diving into languages like Python for custom solutions and functionality.
He shared his screen and instead of seeing a typical page full of Python code in a programming editor, I saw his code neatly organized in a Jupyter Notebook. Sections, explanatory text, images, and visualizations were all mixed in with relatively small snippets of Python code.
I’ll admit I was late to the party on Jupyter! Project Jupyter began life in 2014 as a spin-off of the IPython project, which itself was born way back in 2001. I was just seeing it for the first time, but its potential was obvious: a friendly tool to help data scientists create applications and collaborate in ways that previously had been too difficult. And I was also discovering the Pandas project, which made it easy to quickly manipulate tables and matrices of data.
As a Seeq product team, we began talking with customers about the idea of adding a Python-based analytics environment to our set of applications. We developed the following hypotheses as a result of those discussions:
- Process data is the primary data source for predictive and prescriptive analytics in industrial environments. (Other data is important too.)
- Data Scientists have lots of algorithms and open-source tools in their toolboxes to apply to predictive/prescriptive analytics.
- There are process engineers interested in expanding their analytics efforts with access to Python code and libraries.
- Data Scientists and process engineers need to collaborate seamlessly while analyzing process data.
- Engineers tend to know the data well.
- Data Scientists tend to know the algorithms well.
- Moving data around to make it accessible for analytics can be costly and problematic.
- Predictive and prescriptive analytics outputs must trace back seamlessly to source data and processes to be actionable in a high-consequence environment.
If these hypotheses are correct, then combining Seeq Workbench and Seeq Organizer with access to the innovation in Jupyter Notebooks would be a solution that would improve the outcomes for data scientists and for process engineers – both process engineers collaborating with data scientists, and those who wanted to expand their own analytics efforts with Python libraries.
So what we did is create a Python- and Pandas-specific module called SPy (short for Seeq Python) and publish it to the PyPI package repository. SPy contains three very simple functions:
- search for data across many data sources
- pull data into Pandas DataFrames
- push new data and visualizations to datastores, displays, dashboards, and reports
These functions do some heavy lifting to get data in and out of Pandas DataFrames as fast as possible and with the least amount of friction.
Right away, customers began downloading the SPy module and using it in concert with Seeq Workbench and Seeq Organizer to open up new worlds in analytics productivity. Leveraging the Anaconda Python distribution to run Jupyter locally, or using the excellent AWS SageMaker and Azure Notebooks in the cloud, here is a typical workflow:
- In Seeq Workbench, find the data that is relevant to the topic at hand and explore it interactively.
- Using the Seeq Workbench Tools panel, cleanse and augment the data by removing outliers, applying smoothing filters, and adding context via Conditions and Capsules.
- Execute pull() to bring the data into a Pandas DataFrame within the Jupyter environment.
- Manipulate the data via Python and use matplotlib, seaborn, Plotly or other modules to visualize it in new ways.
- Execute push() to take the data back into Seeq Workbench and/or execute spy.workbooks.push() to publish the visualizations to Seeq Organizer.
Customers were off to the races, but there were a couple of points of friction for us to address. Seeq has many security features that integrate with various authentication and access control schemes – both modern and legacy – and Python can have a hard time leveraging them (e.g. password-less Windows NTLM/Kerberos authentication). Also, customers wanted to create Jupyter Notebooks and schedule them to run (with particular security credentials) at prescribed times.
So we created Seeq Data Lab.
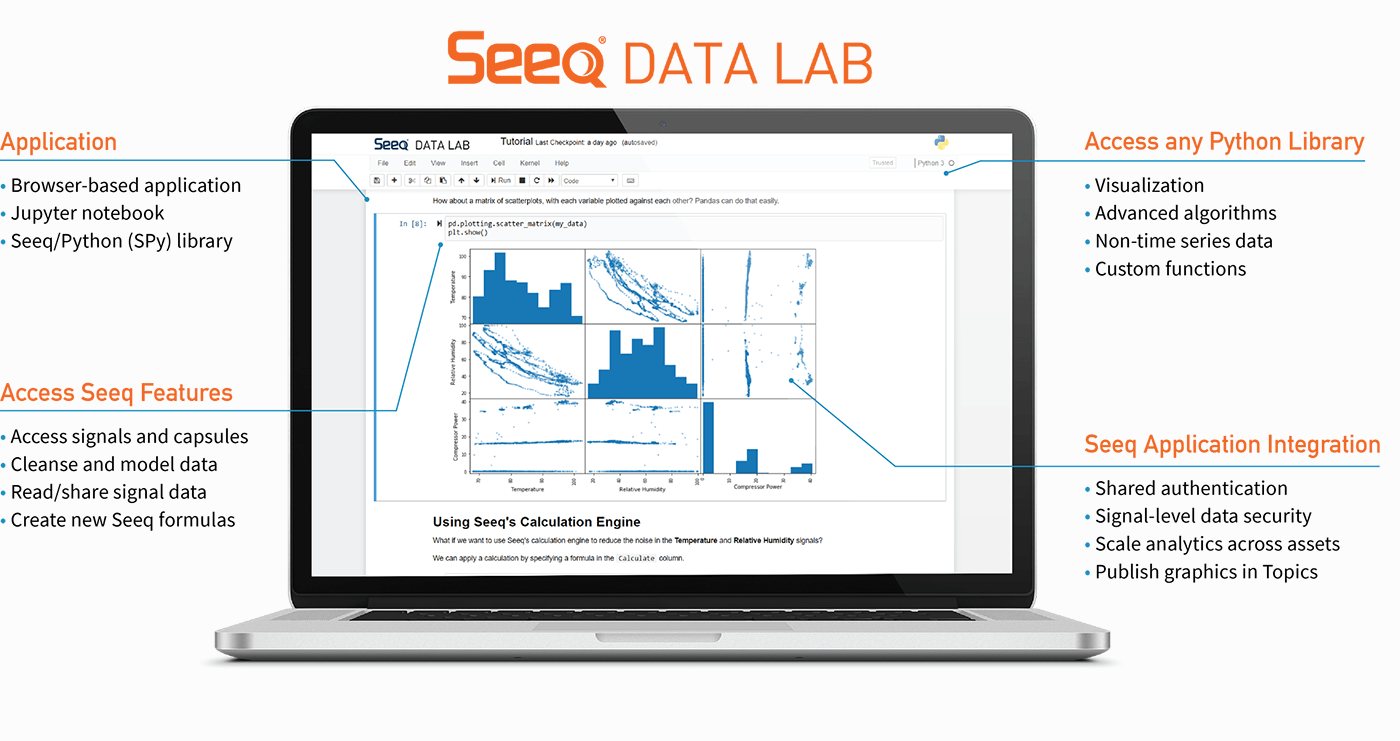
Seeq Data Lab leverages container technology (Docker/Kubernetes) to spawn Jupyter Notebooks in sandboxed environments and integrate seamlessly with the security features of Seeq and its underlying data sources. Seeq Data Lab can be installed on-premise (on customer infrastructure) or can be hosted in the cloud. Customers can now create Seeq Data Lab Projects and manage them just like Seeq Workbench Analyses and Seeq Organizer Topics, sharing and collaborating on them with colleagues.
What we are announcing today is just the start of our efforts to eliminate the “edge” between the analytics enabled in Seeq Workbench and wherever users want to take their analytics. For example, later in 2020, users will be able to schedule a Jupyter Notebook within a Seeq Data Lab Project to run at prescribed times, which will enable process engineers and data scientists to operationalize their notebooks and take their organizations to new levels in the realms of predictive maintenance, exception-based management, and monitoring and diagnostics.
That’s just one idea, we’ll be listening to customer feedback for more input on their use of all Seeq applications. I hope to hear from you!